
How To: Accessing Live NBA Play-By-Play Data, Real Timestamps, And Neon Ridgeline Plots
F5Days For You And Your Friends

Hey everyone,
This is one of those free R tutorials that I occasionally send out to all subscribers — both free and paid. If you don’t care to know how the sausage is made for this newsletter, then I would recommend deleting this email.
On the other hand, if you’ve ever wondered why some people pay for this newsletter, then read on and consider signing up for a paid subscription yourself. It’s $5 a month or $50 for a full year and you get access to the full archive of R tutorials that you can view online at thef5.substack.com.
Today’s tutorial is going to go over how I got the data on timestamps during NBA games to measure how long Giannis Antetokounmpo spends at the free throw line relative to the rest of the league. I’ll also spend some time going over the code for the accompanying visualization. At the end of this post I’ll include the code for creating the other visualization on midrange efficiency in the postseason that also appeared in this week’s newsletter.
{kind=link}
Let’s start off by loading some packages and setting up a custom theme that we’ll use for our chart.
# load packages
library(tidyverse)
library(nbastatR)
library(jsonlite)
library(httr)
library(vroom)
library(extrafont)
library(lubridate)
library(ggfx)
library(ggridges)
# set theme
theme_owen <- function () {
theme_minimal(base_size=9, base_family="Consolas") %+replace%
theme(
panel.grid.minor = element_blank(),
plot.background = element_rect(fill = 'floralwhite', color = 'floralwhite')
)
}The data we’re going to work comes from the NBA’s live play-by-play logs (this is a different data source than the traditional play-by-play logs that we’ve worked with in the past). Here’s an example of the data, which is the live play-by-play data for Game 4 of the Finals between the Bucks and Suns.

The data, like most stuff on stats.nba.com, is stored in JSON format. To get the data in more traditional format, like a dataframe, we just need to run a few lines of code in R. But first, we need to specify some headers in advance so that when we make a request to the NBA’s API we don’t get timed out (h/t Ryan Davis).
# set headers h/t Ryan Davis
headers = c(
`Connection` = 'keep-alive',
`Accept` = 'application/json, text/plain, */*',
`x-nba-stats-token` = 'true',
`X-NewRelic-ID` = 'VQECWF5UChAHUlNTBwgBVw==',
`User-Agent` = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36',
`x-nba-stats-origin` = 'stats',
`Sec-Fetch-Site` = 'same-origin',
`Sec-Fetch-Mode` = 'cors',
`Referer` = 'https://stats.nba.com/players/leaguedashplayerbiostats/',
`Accept-Encoding` = 'gzip, deflate, br',
`Accept-Language` = 'en-US,en;q=0.9'
)The following code uses the headers we specified and extracts the play-by-play data and stores it in a dataframe called df.
url <- "https://cdn.nba.com/static/json/liveData/playbyplay/playbyplay_0042000404.json"
res <- GET(url = url, add_headers(.headers=headers))
json_resp <- fromJSON(content(res, "text"))
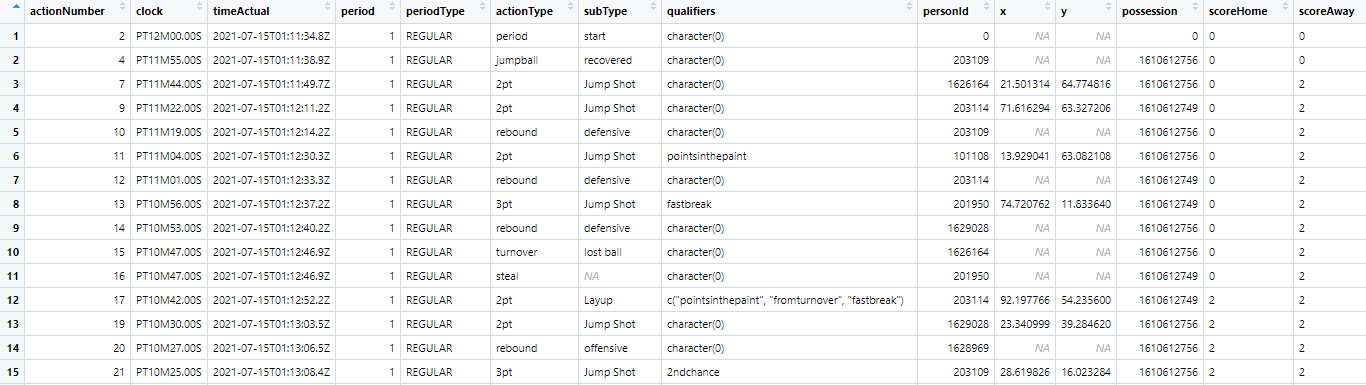
df <- data.frame(json_resp[["game"]][["actions"]])Here’s a snapshot of what it should look like:
To make our chart we need the play-by-play data for every game from the regular season. The fastest way to get all the data is with a function. But first, we need to get a list of all the game IDs from this season, which we can get with {nbastatR} package.
So lets get all the game IDs and then create our function for getting the play-by-play data.
# get game logs from the reg season
game_logs <- game_logs(seasons = 2021,
result_types = 'team',
season_types = "Regular Season")
# Get a list of distinct game ids
game_ids <- game_logs %>%
select(idGame) %>%
distinct()
# create function that gets pbp logs from the 2020-21 season
get_data <- function(id) {
url <- paste0("https://cdn.nba.com/static/json/liveData/playbyplay/playbyplay_00", id, ".json")
res <- GET(url = url, add_headers(.headers=headers))
json_resp <- fromJSON(content(res, "text"))
df <- data.frame(json_resp[["game"]][["actions"]])
df$gameid <- id
return(df)
}Now we just need to run every game ID through this function and store the results in one giant dataframe.
After that, we’re going to find all the instances of free throw attempts in our data and calculate how much time elapsed from when the player attempted their free throw from whatever action that preceded the free throw.
Note that these two steps (particularly the first one) take a few minutes to run and if you don’t want to wait that long, just download the cleaned data I already uploaded to GitHub.
# get data from all ids (takes awhile)
pbpdat <- map_df(game_ids$idGame, get_data)
# calculate time elapsed between a free throw and whatever action came before it
df <- pbpdat %>%
arrange(gameid, orderNumber) %>%
mutate(dtm = as_datetime(timeActual),
ptm = lag(dtm),
elp = dtm-ptm,
pact = lag(actionType),
psub = lag(subType),
pmake = lag(shotResult)) %>%
filter(actionType == "freethrow",
elp > 0) %>%
select(gameid, clock, actionNumber, orderNumber, subType, pact, psub, dtm, ptm, pmake, elp, personId, playerNameI, shotResult, period)
###
# read in cleaned data from GitHub, if you want
df <- vroom("https://raw.githubusercontent.com/Henryjean/data/main/cleanpbplogs2021.csv")The last of bit of data wrangling we need to do before making our chart is limit our dataset so that we’re only looking at the time in between consecutive free throw attempts. In other words, we don’t care how much time elapsed between a shooting foul and a player’s first free throw. Nor do we care about instances where a substitution occurred in between a player’s first and second free throw. So I’m just going to look at instances where the previous action was also a free throw.
In this step we’re also going to calculate the number of observations we have for each player and the average amount of time that elapsed between their consecutive attempts. We’ll limit our data so that we’re only looking at players that we have at least 50 observations for.
# find average time elapsed between 1st and 2nd (or 2nd and 3rd) FTs when previous action was a FT
# psub == "offensive" means player missed preceding free throw
df <- df %>%
filter((subType == "2 of 2" & (psub == "1 of 2" | psub == "offensive")) |
(subType == "2 of 3" & (psub == "1 of 3" | psub == "offensive")) |
(subType == "3 of 3" & (psub == "2 of 3" | psub == "offensive"))
) %>%
group_by(playerNameI, personId) %>%
mutate(count = n(),
avgtime = mean(elp)) %>%
filter(count >= 50) %>%
ungroup() It’s chart time.
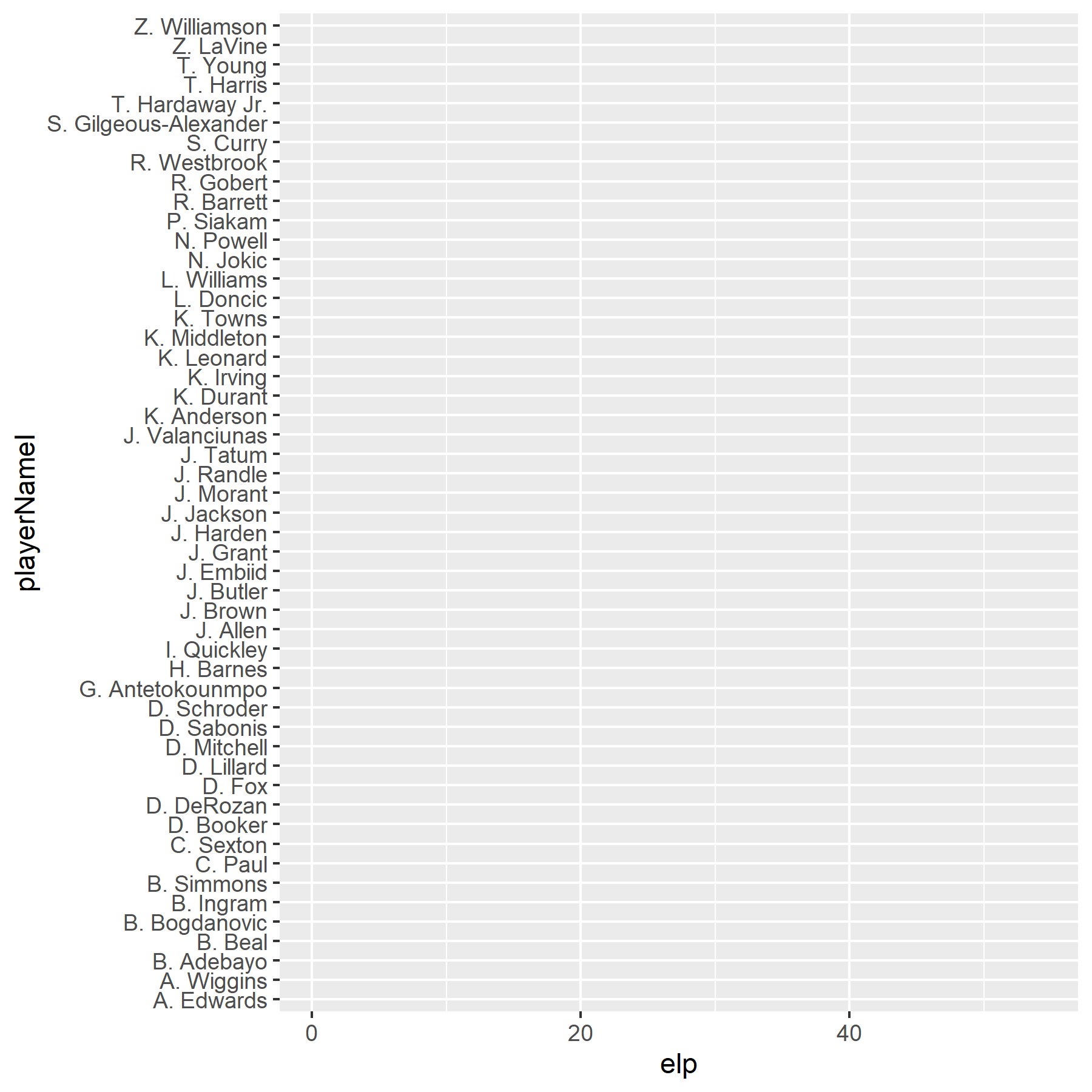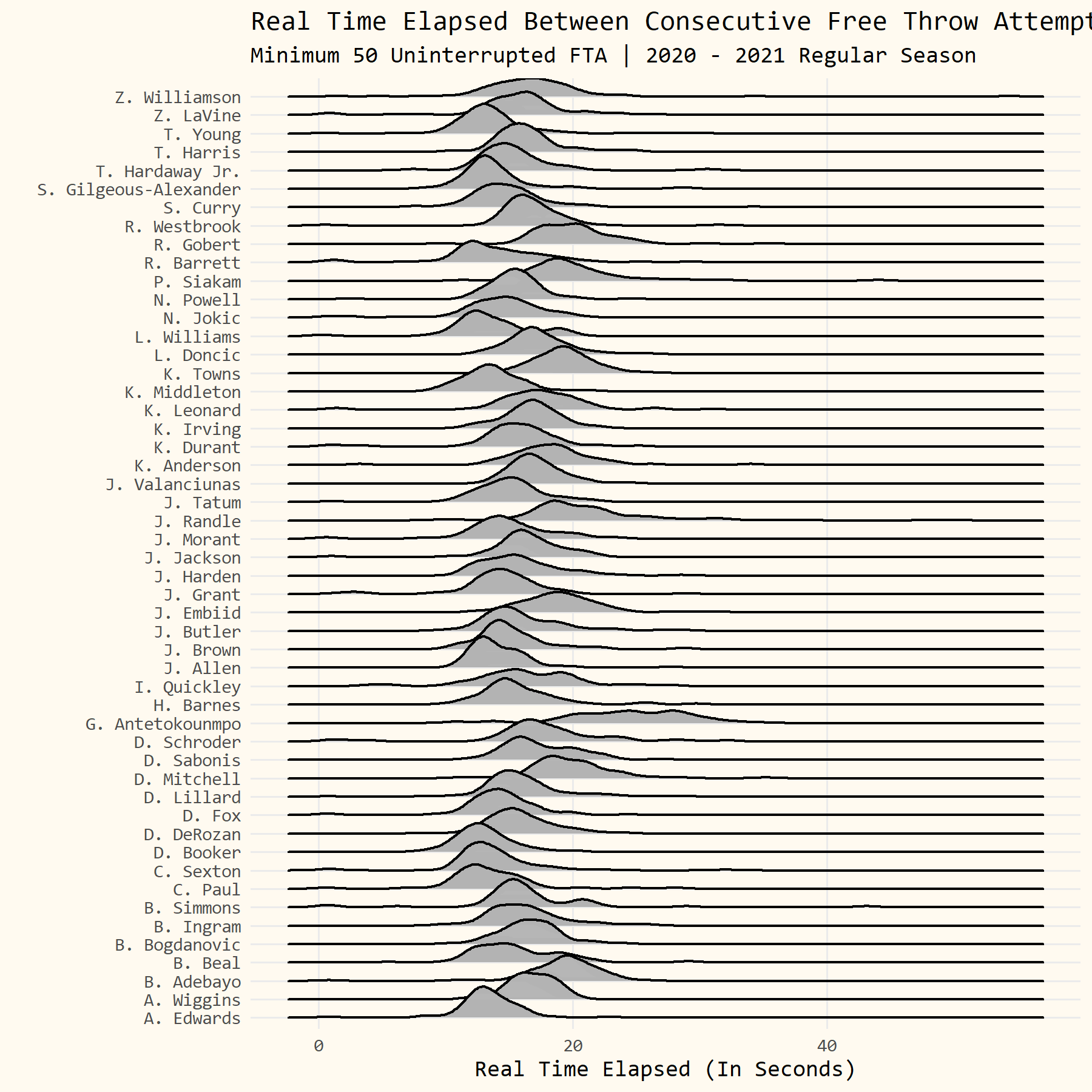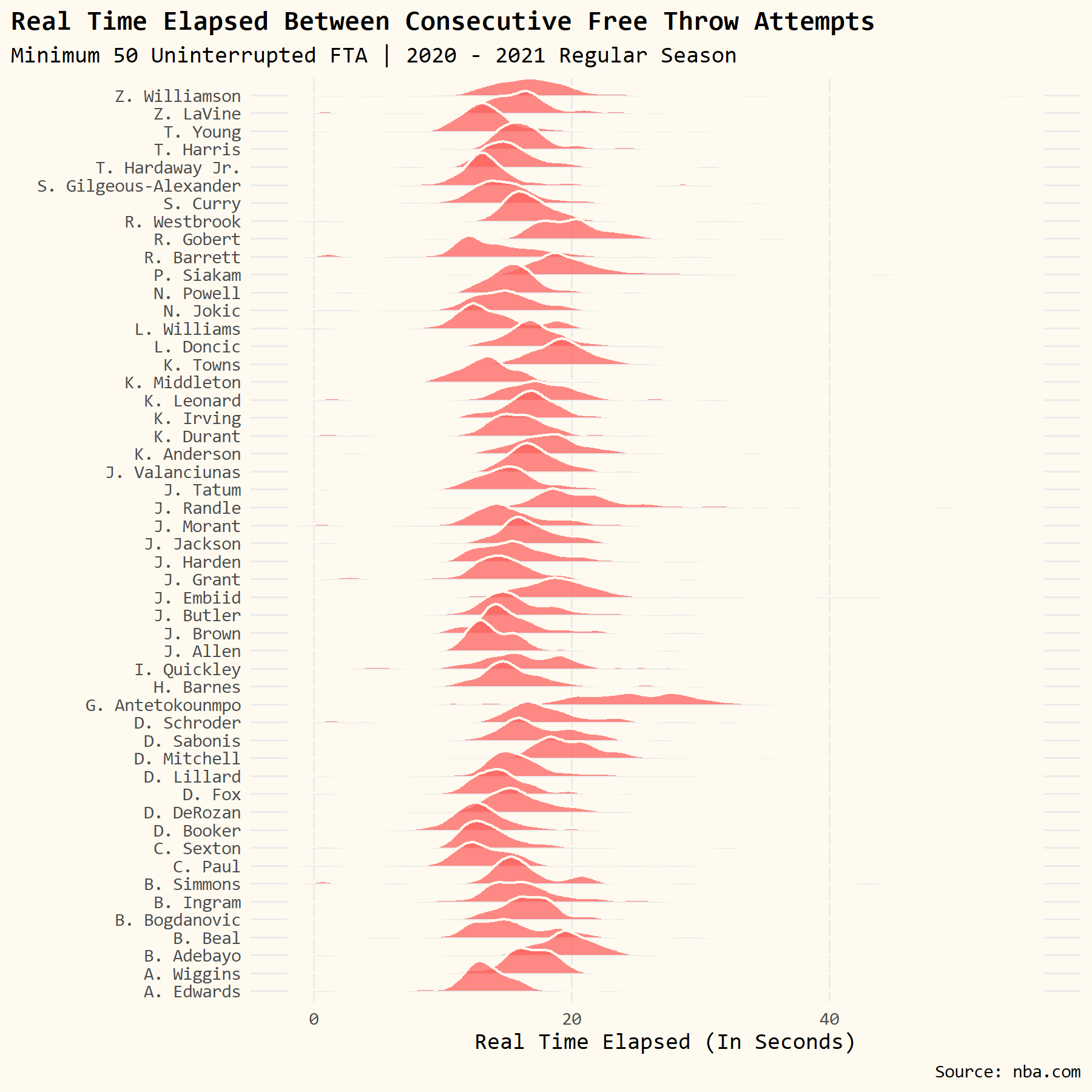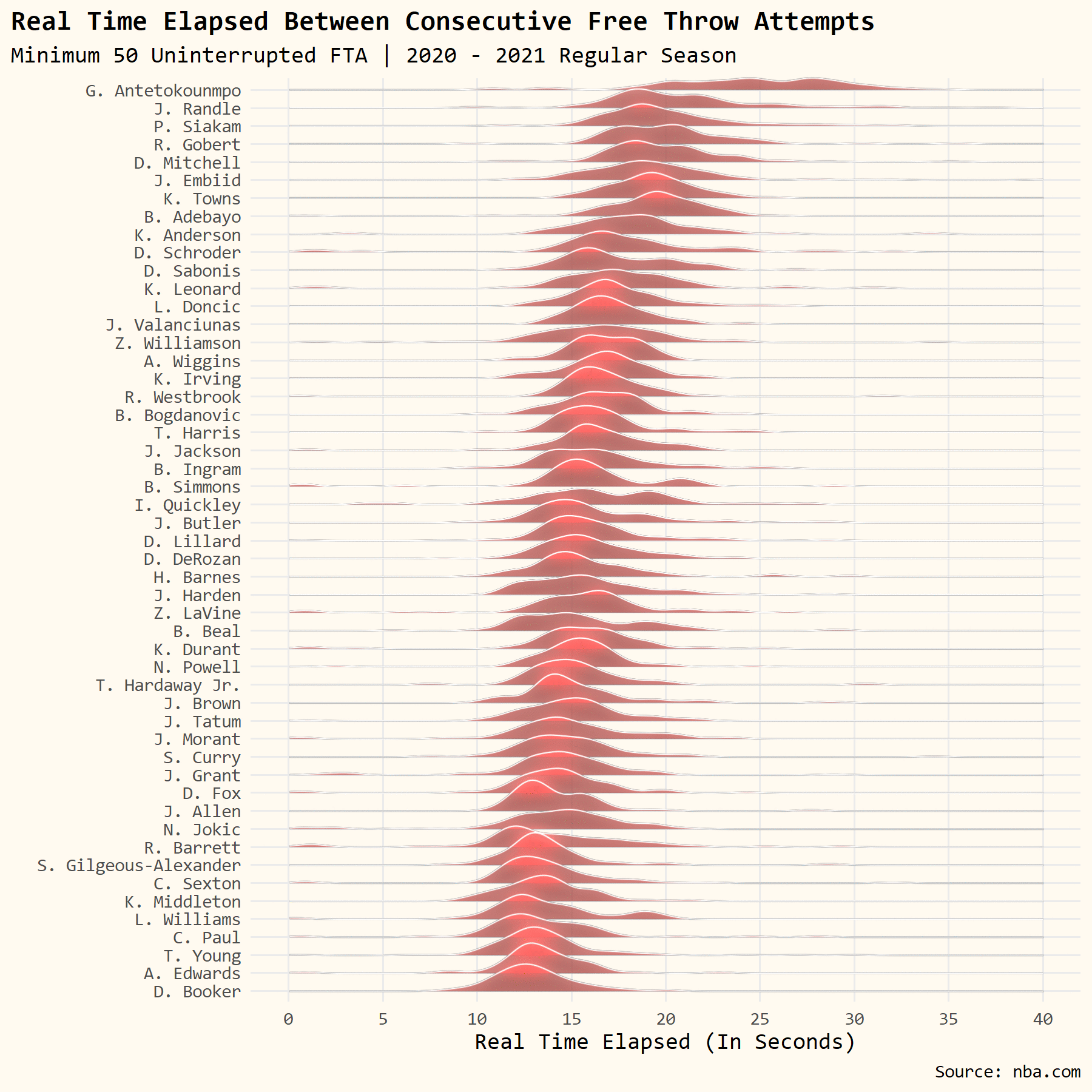
We’re going to make use of the {ggfx} and {ggridges} package to draw little neon-colored distributions for each player and then order them by their average time elapsed between free throws.
You can fiddle with the bandwidth option to make the distributions smoother (higher bandwidth value) or less smooth (smaller bandwidth value) if you want.
# make chart
df %>%
# order players by avgtime elapsed
ggplot(aes(x = elp, y = fct_reorder(playerNameI, avgtime))) +
# add ridgelines with ggfx tweaks
with_bloom(geom_density_ridges(size = .25,
color = 'white',
fill = "#FD625EFF",
scale = 3,
alpha = .75,
bandwidth = .75),
color = "white",
sigma = 10,
keep_alpha = TRUE) +
# format x-axis
scale_x_continuous(limits = c(0, 40),
breaks = seq(0, 40, 5)) +
# turn off clipping
coord_cartesian(clip = 'off') +
# add custom theme
theme_owen() +
# make thematic tweaks
theme(legend.position = 'none',
axis.text.y = element_text(size = 6, margin = margin(0,-15,0,0)),
plot.title.position = 'plot',
plot.title = element_text(face = 'bold')) +
# add axis titles, plot title, subtitle, and caption
labs(x = "Real Time Elapsed (In Seconds)",
y = "",
title = "Real Time Elapsed Between Consecutive Free Throw Attempts",
subtitle = "Minimum 50 Uninterrupted FTA | 2020 - 2021 Regular Season",
caption = "Source: nba.com")
# save plot
ggsave("RidgeLinePlot.png", w = 6, h = 6, dpi = 300)
I’m not going to go line by line here, but here’s the code for how to re-create the other chart from this week’s newsletter, which showed players career FG% on short and long midrange shots during the postseason.
# load packages
library(tidyverse)
library(jsonlite)
library(janitor)
library(extrafont)
library(ggrepel)
library(scales)
# set theme
theme_owen <- function () {
theme_minimal(base_size=10, base_family="Consolas") %+replace%
theme(
panel.grid.minor = element_blank(),
plot.background = element_rect(fill = 'floralwhite', color = "floralwhite")
)
}
# write fucntion to get player stats by year in the playoffs
get_data <- function(year) {
url <- paste0("https://api.pbpstats.com/get-totals/nba?Season=", year, "&SeasonType=Playoffs&Type=Player")
json_data <- fromJSON(paste(readLines(url), collapse=""))
pbp <- json_data[["multi_row_table_data"]]
pbp <- pbp %>%
select(Name, EntityId, Minutes, FG2A, FG3A,
ShortMidRangeFGA, ShortMidRangeFGM, ShortMidRangeAccuracy, ShortMidRangePctAssisted,
LongMidRangeFGA, LongMidRangeFGM, LongMidRangeAccuracy, LongMidRangePctAssisted) %>%
clean_names()
pbp$season <- year
return(pbp)
}
# get data (takes a minute)
dat <- map_df(c("2020-21", "2019-20",
"2018-19", "2017-18",
"2016-17", "2015-16",
"2014-15", "2013-14",
"2012-13", "2011-12",
"2010-11", "2009-10",
"2008-09", "2007-08",
"2006-07", "2005-06",
"2004-05", "2003-04",
"2002-03", "2001-02",
"2000-01"),
get_data)
# calculate career FG% on short and long midrangers
# filter for those that have both 100 in each category
df <- dat %>%
group_by(entity_id, name) %>%
summarise(short_mid_range_fga = sum(short_mid_range_fga, na.rm = TRUE),
short_mid_range_fgm = sum(short_mid_range_fgm, na.rm = TRUE),
short_mid_range_accuracy = short_mid_range_fgm / short_mid_range_fga,
long_mid_range_fga = sum(long_mid_range_fga, na.rm = TRUE),
long_mid_range_fgm = sum(long_mid_range_fgm, na.rm = TRUE),
long_mid_range_accuracy = long_mid_range_fgm / long_mid_range_fga) %>%
filter(short_mid_range_fga >= 100 & long_mid_range_fga >= 100)
# make plot
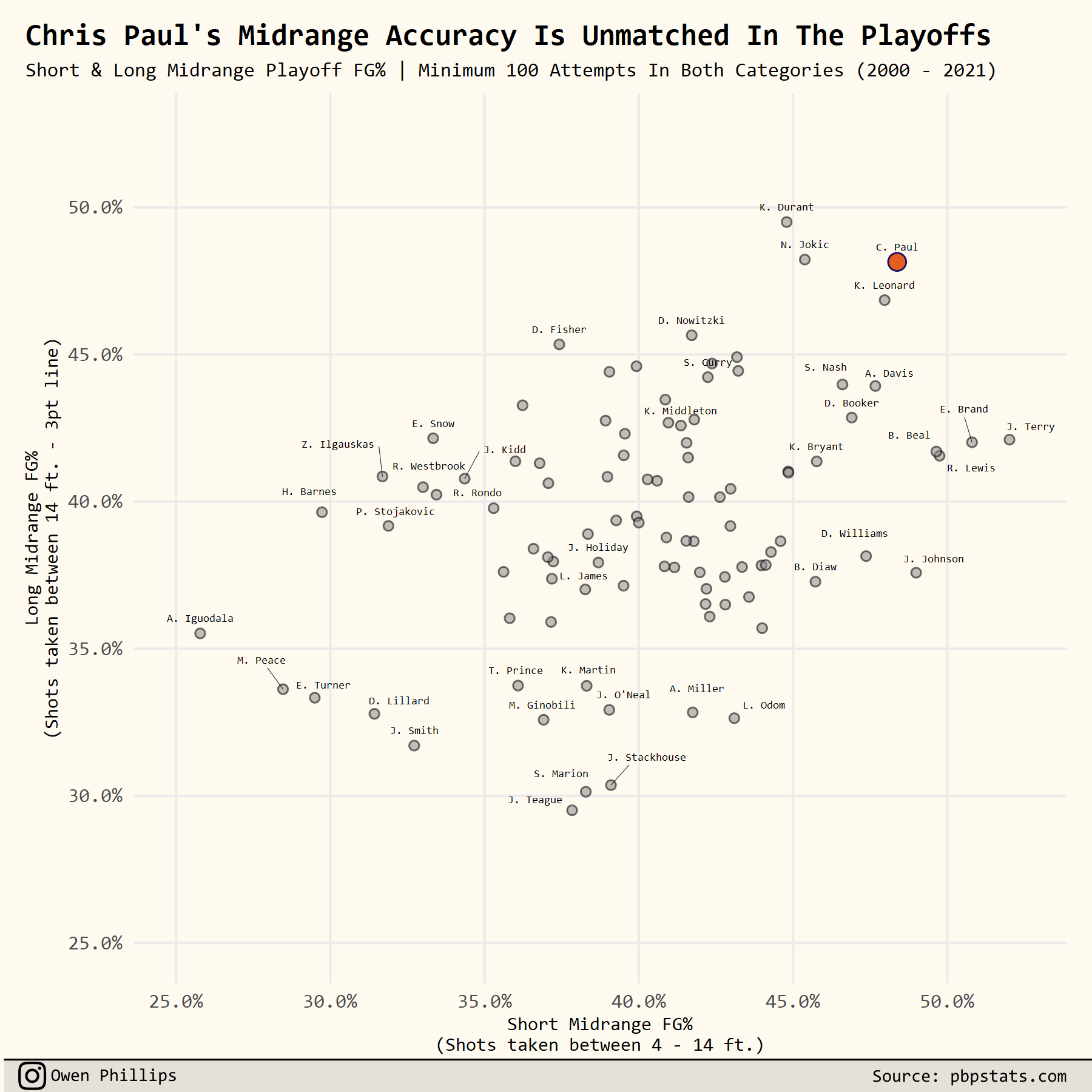
df %>%
ggplot(aes(x = short_mid_range_accuracy,
y = long_mid_range_accuracy,
label = paste0(substr(name, 1, 1), ". ", word(name, -1)))) +
# add points for everyone but CP3
geom_point(data = . %>% filter(name != "Chris Paul"),
size = 1.5,
alpha = .55,
shape = 21,
fill = 'gray55',
color = 'black') +
# add point for CP3
geom_point(data = . %>% filter(name == "Chris Paul"),
size = 3,
shape = 21,
fill = '#E56020',
color = "#1D1160") +
# add labels for players that meet certain criteria
geom_text_repel(data = . %>% filter(short_mid_range_accuracy >= .45 |
short_mid_range_accuracy <= .35 |
long_mid_range_accuracy >= .45 |
long_mid_range_accuracy < .35 |
name %in% c("LeBron James", "Stephen Curry", "Jrue Holiday", "Khris Middleton")),
size = 1.5,
family = "Consolas",
alpha = 1,
nudge_y = .005,
segment.size = .1) +
# format axis
scale_x_continuous(limits = c(.25, .525),
labels = percent) +
scale_y_continuous(limits = c(.25, .525),
labels = percent) +
# add theme
theme_owen() +
# thematic tweaks
theme(plot.title.position = 'plot',
plot.title = element_text(face = 'bold'),
plot.subtitle = element_text(size = 8),
axis.title = element_text(size = 7.5)) +
# add axis titles, plot titles, subtitles, and caption
labs(x = "Short Midrange FG%\n(Shots taken between 4 - 14 ft.)",
y = "Long Midrange FG%\n(Shots taken between 14 ft. - 3pt line)",
title = "Chris Paul's Midrange Accuracy Is Unmatched In The Playoffs",
subtitle = "Short & Long Midrange Playoff FG% | Minimum 100 Attempts In Both Categories (2000 - 2021)",
caption = "Source: pbpstats.com")
ggsave("CareerMidrange.png", w = 6, h = 6, dpi = 300, type = 'cairo')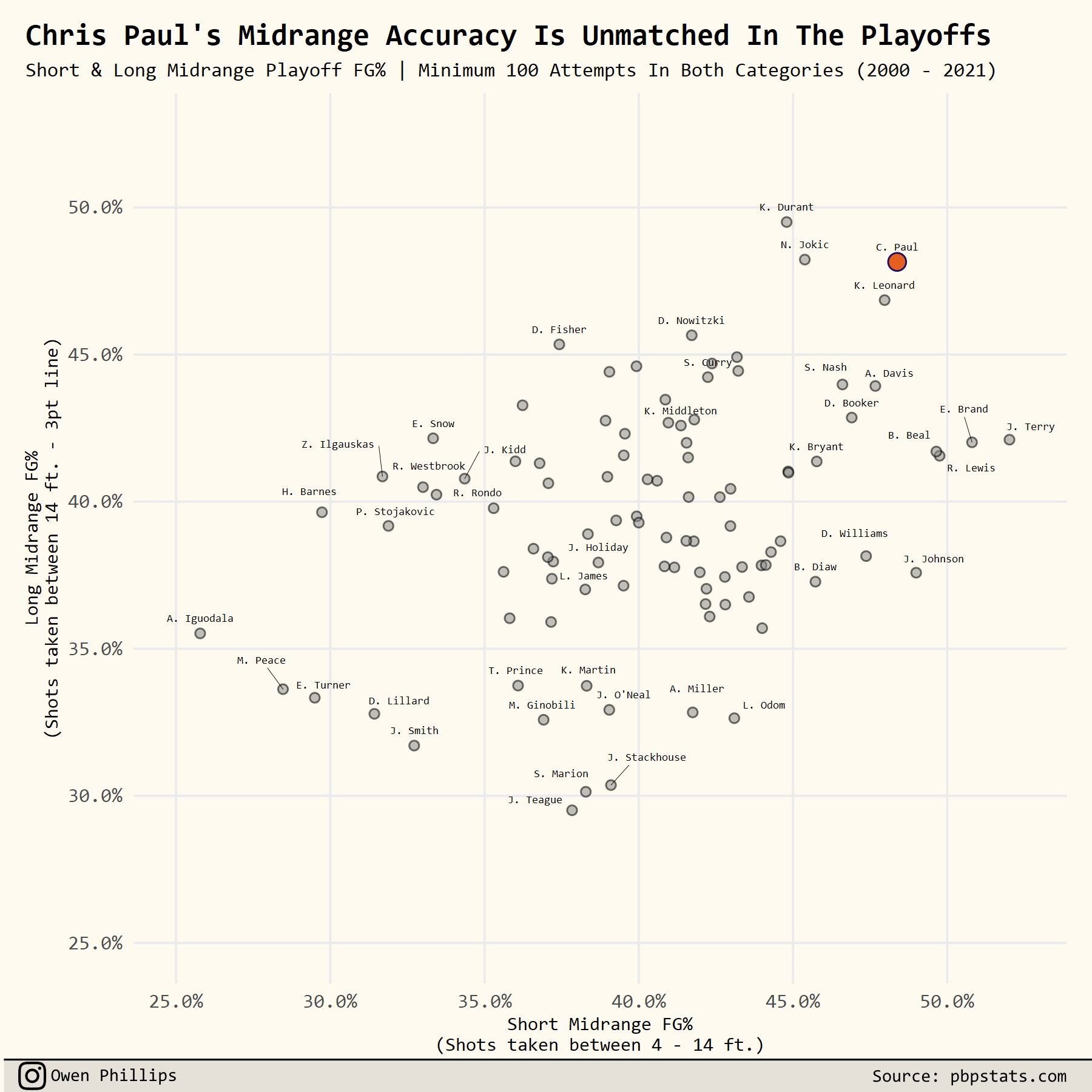
Great post Owen, do you know if closest defender distance is still available?
Hi Owen, what's your thoughts on Python?